Aishwarya Pothula
A Brief Summary of World Models
Inspired by
- The decisions and actions of humans are based on a mental model that we develop of our environment from what we can perceive with our senses.
- Humans depend on selected concepts and relationships between the entities in the real-environment to represent the environment in their mind.
- Our brain learns an abstract representation of the spatial and temporal aspects if information.
- Ex: We remember an abstract description of a scene that we have seen
- Our behavior is a result of the predictive analysis our brain does on the stored mental model w.r.t the input it receives.
- Ex:being able to process and hit a 100 mph ball accurately. We are able to instinctively predict the motion of the ball and swing the bat faster than the time it takes for the visual signals to reach our brain. We can quickly and subconsciously act on our predictions without having to consciously roll out possible future scenarios to form a plan of action.
- The idea is that for many learning problems, an RL model would benefit from having a spatial and temporal representation of past and present states, and a good predictive model for future
Introduction
- Building 'Generative Neural Network' models for popular RL environments
- World Models can be quickly trained (unsupervised) to learn a compressed spatial and temporal representation of the environment.
- A compact and simple policy can be learned for the required task by giving the feature extracted by the world models as inputs to the agent
- The agent can also be made to depend fully on its own dream environment generated by the world model for training.
- This policy is later brought into the actual environment
- To overcome the problem of agent taking advantage of the imperfections in the internal model, a temperature parameter is used
- A temperature parameter allows for the control of randomness of predictions by scaling the logits before applying softmax. Performing softmax on larger values makes the system more confident
Agent Model
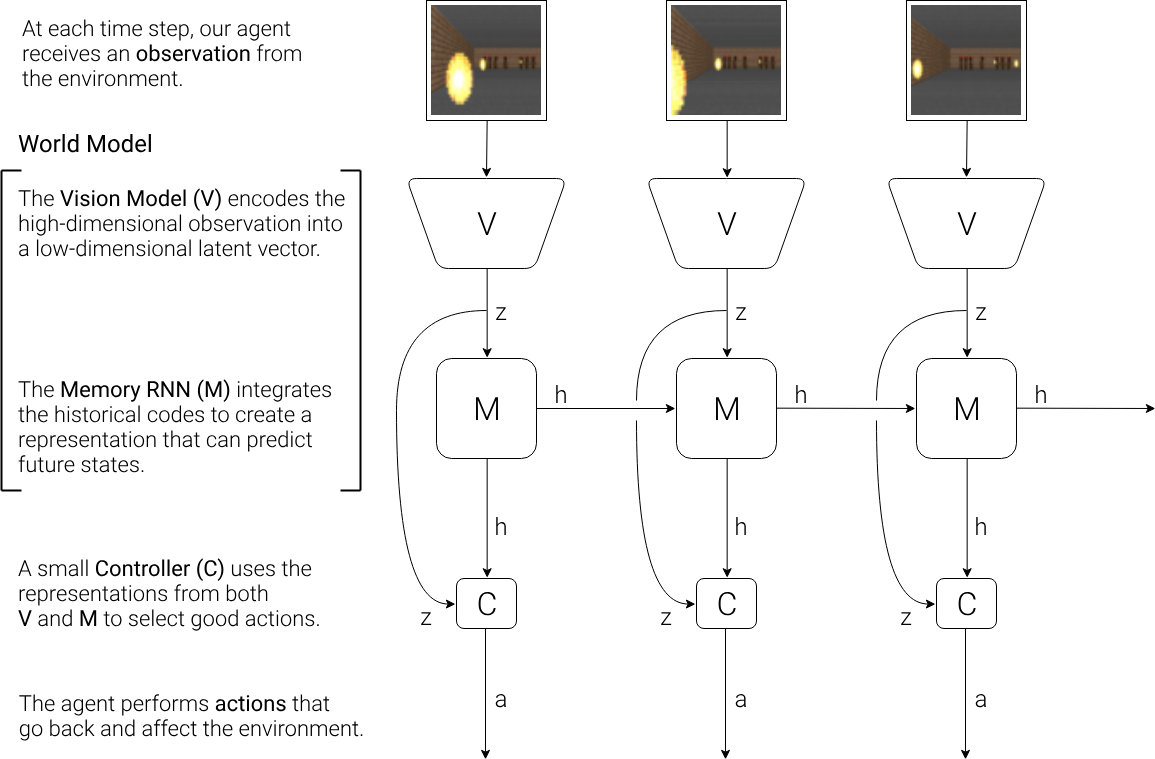
- Visual Sensory component
- Variational Encoder V compresses what it sees into small representative code
- Memory component
- Makes predictions about future code based in historical information
- Decision making component
- Decides the action to be taken based only on the representations created by its vision and memory components
VAE(V) Model
- The role of V Model is to learn an abstract , compressed representation of each observed input frame
- Environment provides V Model or VAE with high dimensional 2D input observation at each time step t which it then compresses into a low dimensional latent vector Zt
- This vector can be later used to reconstruct the actual image
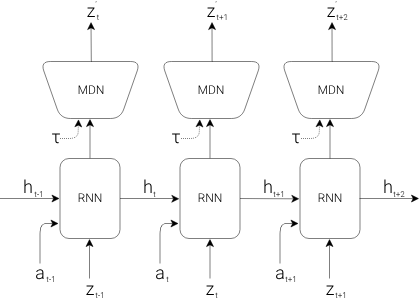
MDN-RNN (M) Model
- M model compresses what happens temporally.
- M Model serves as the predictive model of the future Z vectors that V is expected to produce
- Because of the stochastic nature of environments, RNN is trained to output a probability density function p(z) instead of a deterministic prediction.
- p(z) is approximated as a mixture Gaussian distribution and the RNN is trained to output p(zt+1) given the current and past information available to it.
- P(zt+1∣at,zt,ht)
- at is the action taken at time t
- ht is the hidden state if RNN at time t
Controller (C) Model
- Model C role is to determine the actions in order to maximize expected reward during rollout of environment
- C is a single layer linear model which maps zt and ht directly to at
- at=Wc[ztthtt]+bcc
- Wc and bc are the weight matrix and bias vector
- They map the concatenated input vector [ztht] to the output action vector at
- Model C is deliberately made simple and small
- It is trained separately from V and M
- This is to ensure that most of the agent's complexity lies in V and M(world model)
Some considerations and reasons
- Traditional RL algorithms, being bottlenecked by the credit assignment problem
- Hence they cannot be used to learn the multitude of weights of a large RNN model.
- So,usually, in practice, smaller networks are used as they iterate faster to a good policy during training
- Being able to train efficient large RNN based agents would be ideal
- Backpropagation algorithm can be used to train large neural networks efficiently.
- In this network large neural networks are trained to do RL tasks
- Agent is divided into a large world model and a small controller model.
- The large neural network is trained to learn a model of the agent's world in an unsupervised training.
- Subsequently, the controller is trained to learn to perform tasks using this world model.
- The small controller allows for greater focus on credit assignment problem on a small search space
- The capacity and expressiveness via the larger model are also not sacrificed
- By training the agent through the world model, it can be shown that it can learn a compact policy to perform its task
